
课程报告复现第一期

课程报告复现第一期
Yusialone第一期 数据分析作业复现
1 | # R代码完整解释 |
这里加载了三个R包:
readxl: 用于读取Excel文件dplyr: 用于数据处理和操作ggplot2: 用于数据可视化
读取数据
1 | sheet1 <- read_excel("data/tmp001.xls") |
从5个Excel文件中读取数据,每个文件对应一个数据表。
1 | loandata <- bind_rows(sheet1, sheet2, sheet3, sheet4, sheet5) |
将5个数据表合并成一个大的数据框loandata。
数据处理
1 | df1 <- filter(loandata, FSTR_LOOPGROUPID == "NHNX40(1)") |
从loandata中筛选出FSTR_LOOPGROUPID为”NHNX40(1)”的数据,存储在df1中。
1 | dftime <- data.frame() |
这段代码查找并打印df1中重复的时间戳。
1 | Sys.setenv(TZ = 'UTC') |
这部分代码:
- 设置系统时区为UTC
- 找出重复时间戳的数据
- 计算重复数据的4-6列的平均值
- 移除重复数据,并用平均值替换重复时间戳的数据
创建时间序列
1 | start_time<-as.POSIXct("2010-04-18 00:00:00", tz = "UTC") |
这段代码创建了一个时间序列,并将其与数据合并,找出缺失值。
填充缺失值
1 | for(i in dfqueshi$num) |
这个循环用前三个非缺失值的平均值填充缺失数据。
1 | for(i in dfqueshi$num) |
为所有缺失数据行添加FSTR_LOOPGROUPID值。
数据转换
1 | df5<-df4 |
创建数据副本并调整FINT_VOLUME值。
5分钟数据聚合
1 | df5min <- df5min %>% arrange(df5min$FDT_TIME) |
这段代码对数据进行5分钟的聚合,计算平均值等统计量。
15分钟数据聚合
1 | df15min <- df15min %>% arrange(df15min$FDT_TIME) |
这段代码对数据进行15分钟的聚合,计算平均值等统计量。
每日数据处理
1 | dfday<-df5 |
这段代码处理每日数据,包括20秒、5分钟和15分钟的聚合。
计算每日5分钟和15分钟平均值
1 | new_df_first_day_5min <- df_first_day_5min %>% |
这段代码计算每日数据的5分钟和15分钟平均值。
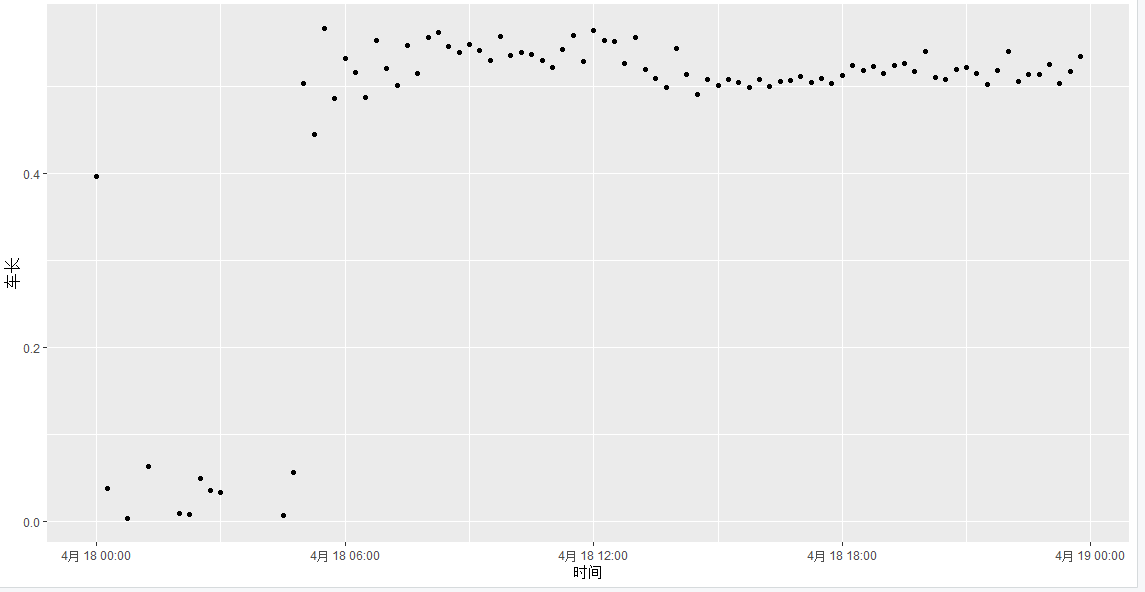
计算车辆长度
1 | new_df_first_day_15min$midu<-new_df_first_day_15min$FINT_VOLUME/new_df_first_day_15min$FINT_SPEED |
这段代码计算了车辆密度和平均车长。
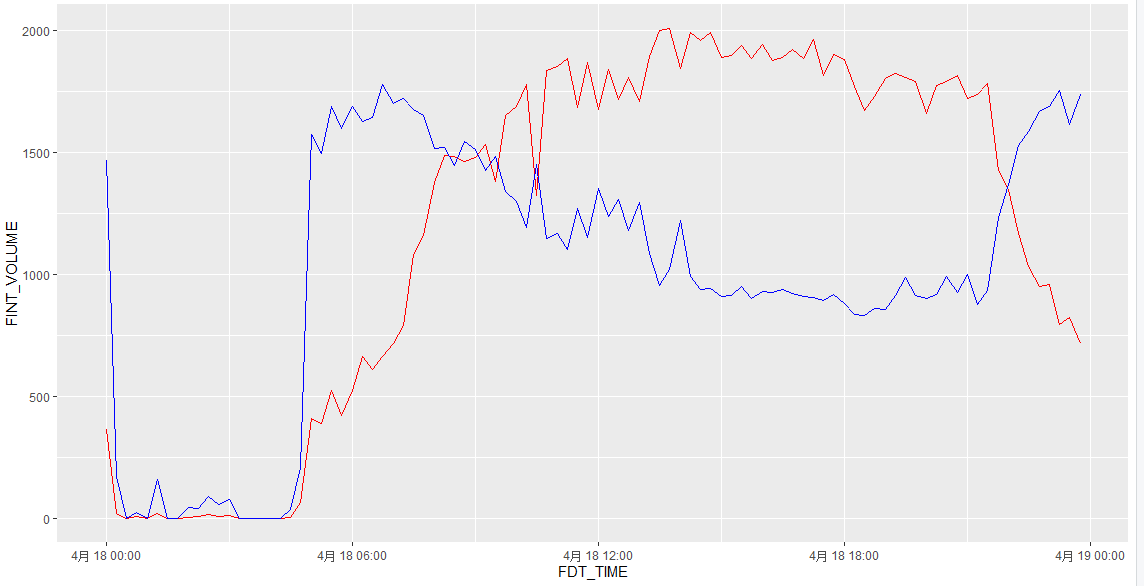
数据可视化
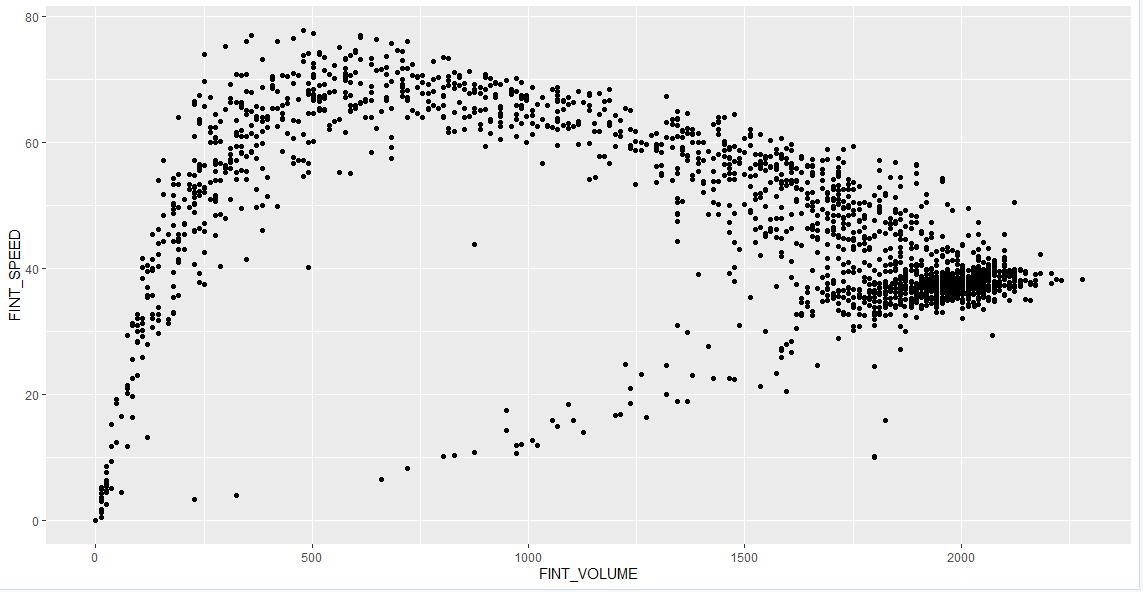
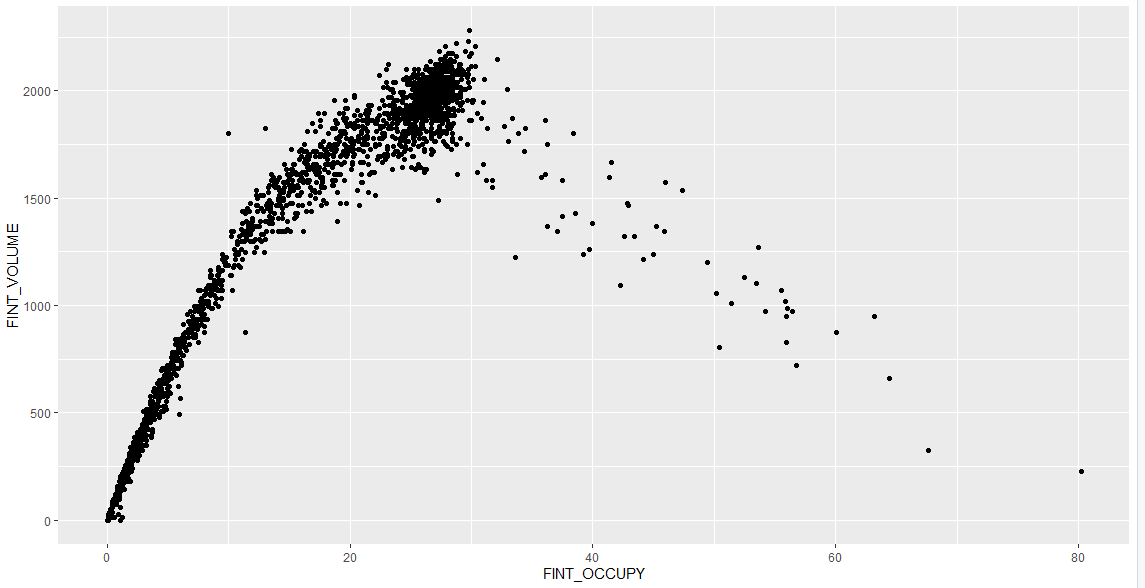
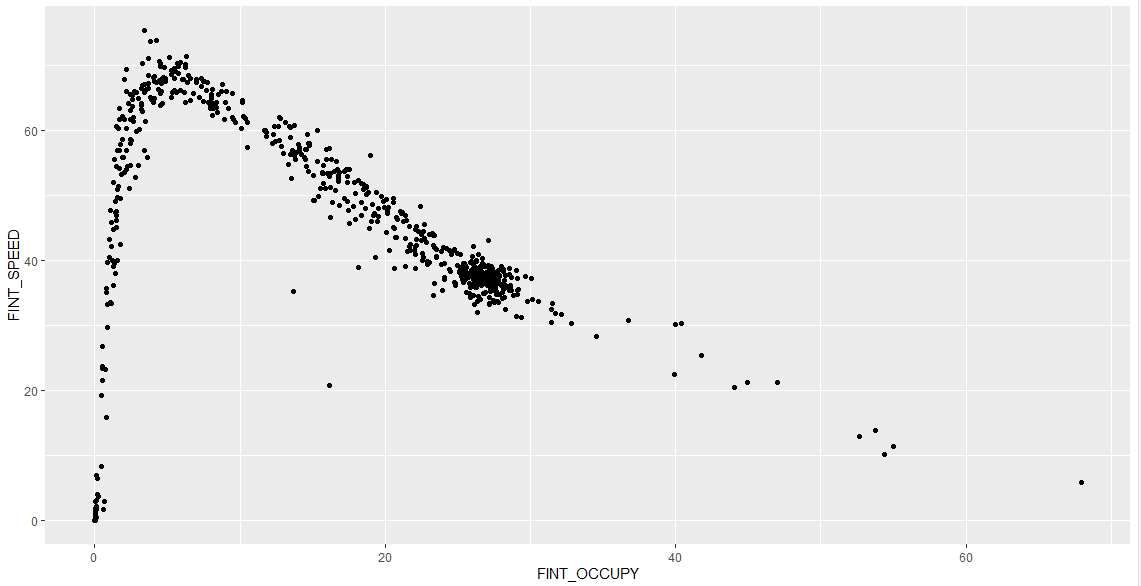
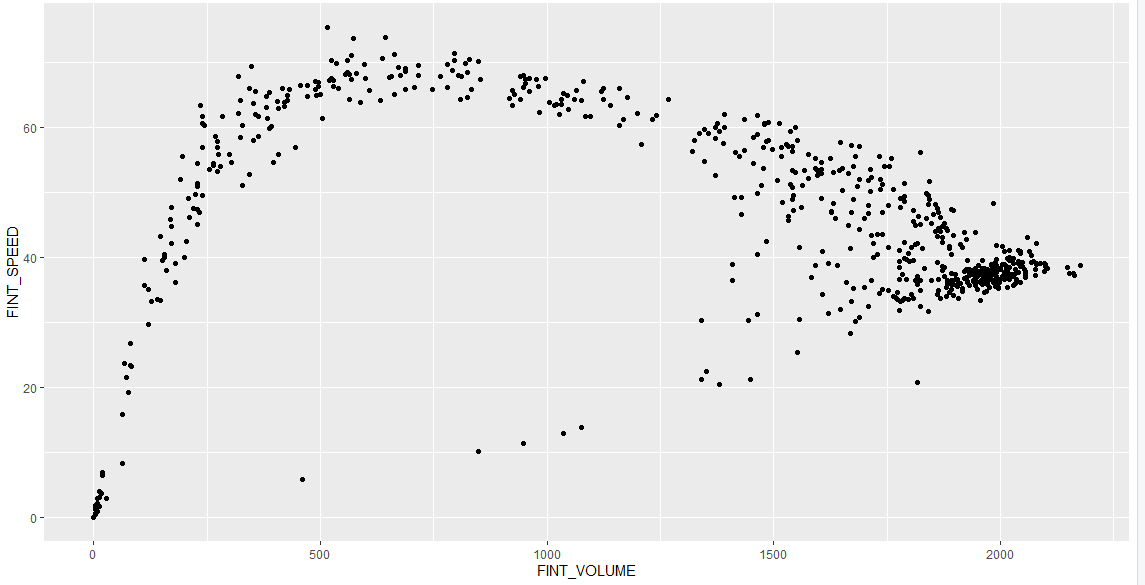
1 | ggplot(df20s, aes(x = FINT_OCCUPY, y = FINT_SPEED)) + |
以下是部分图像展示:
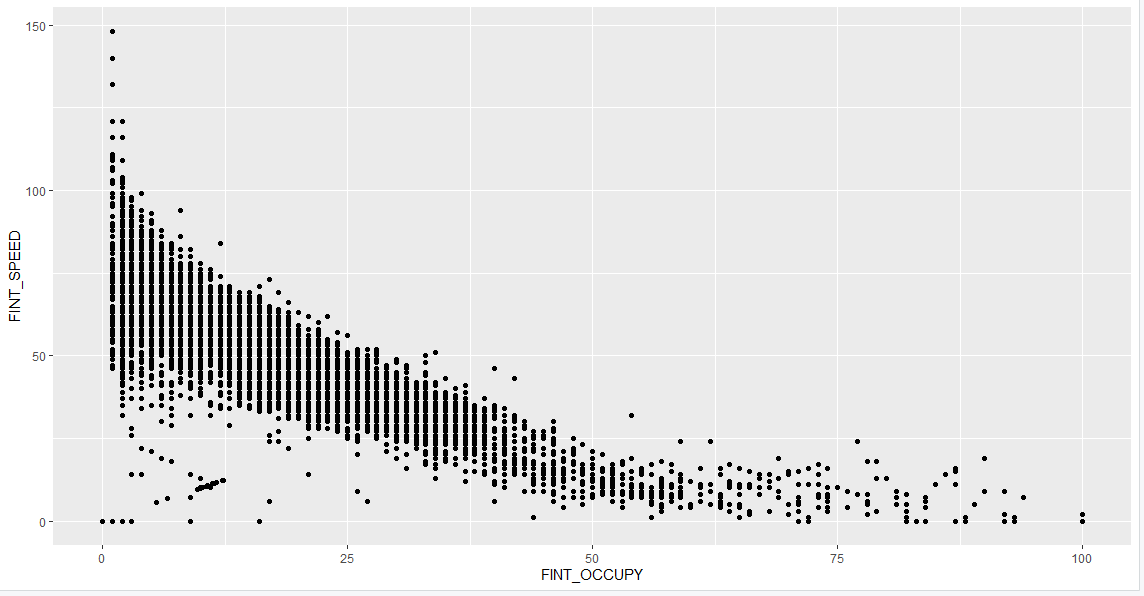
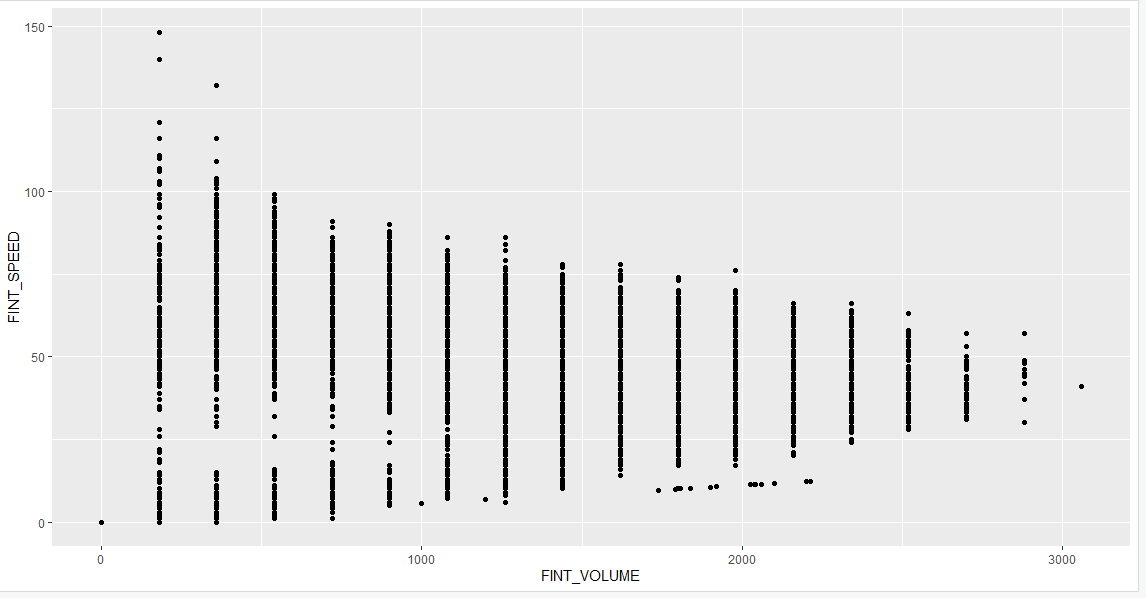
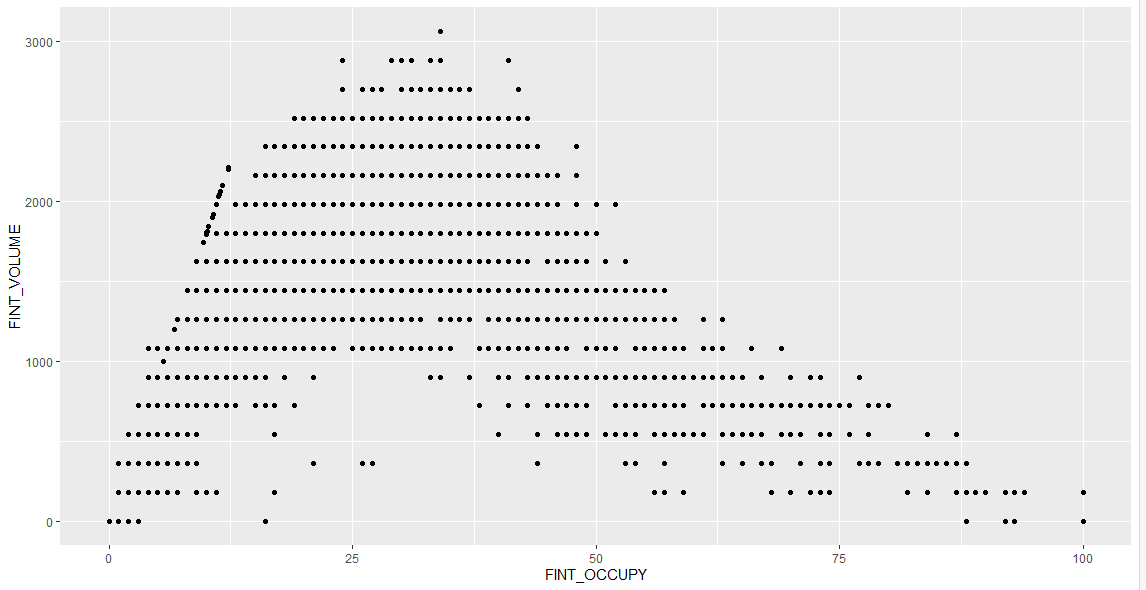
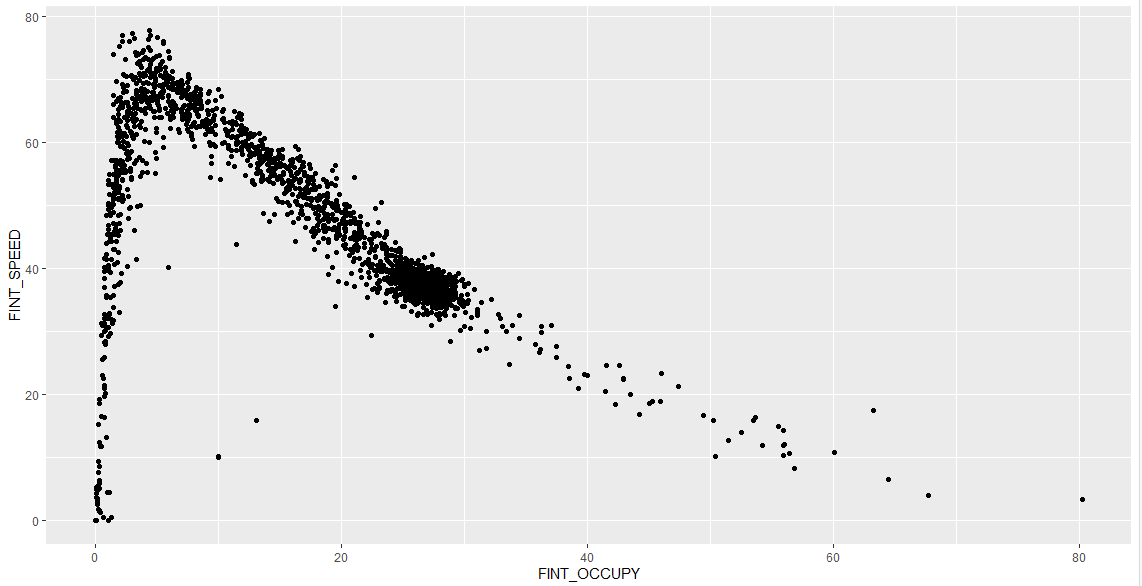
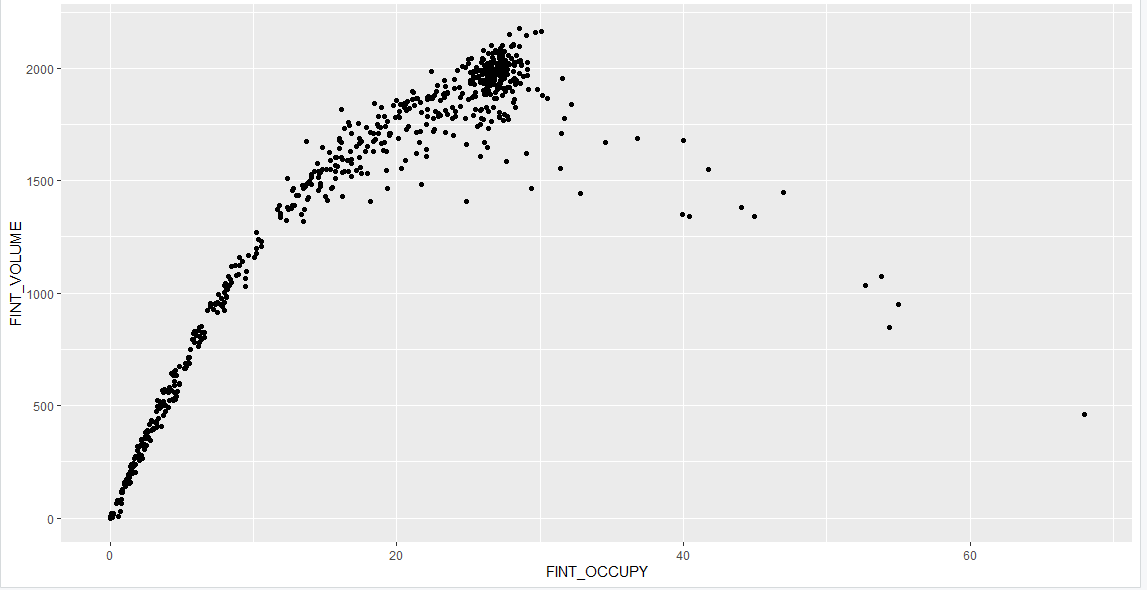
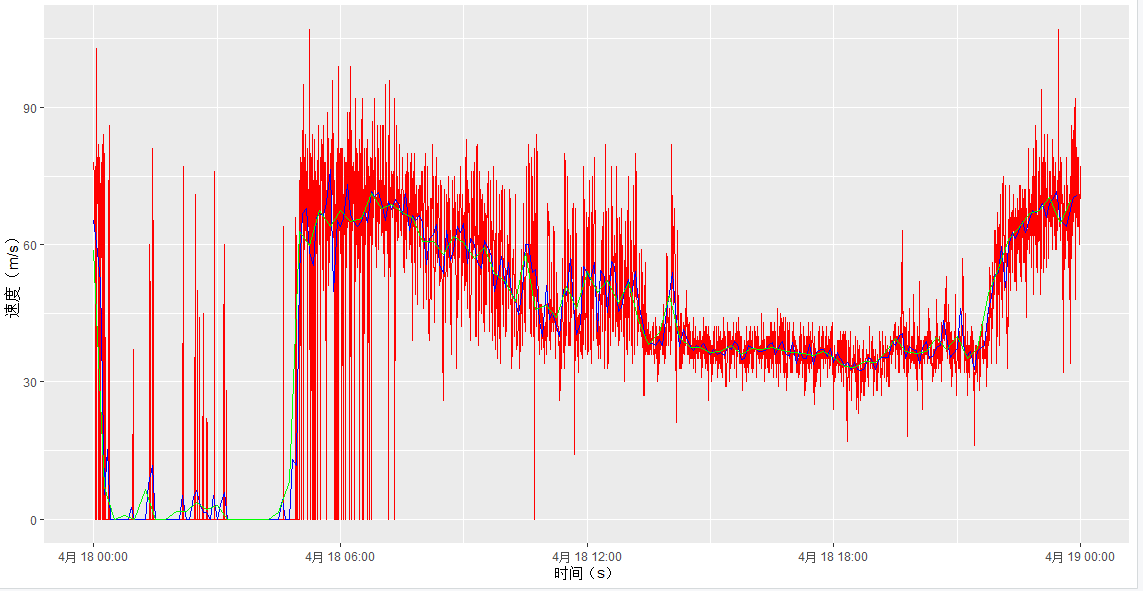
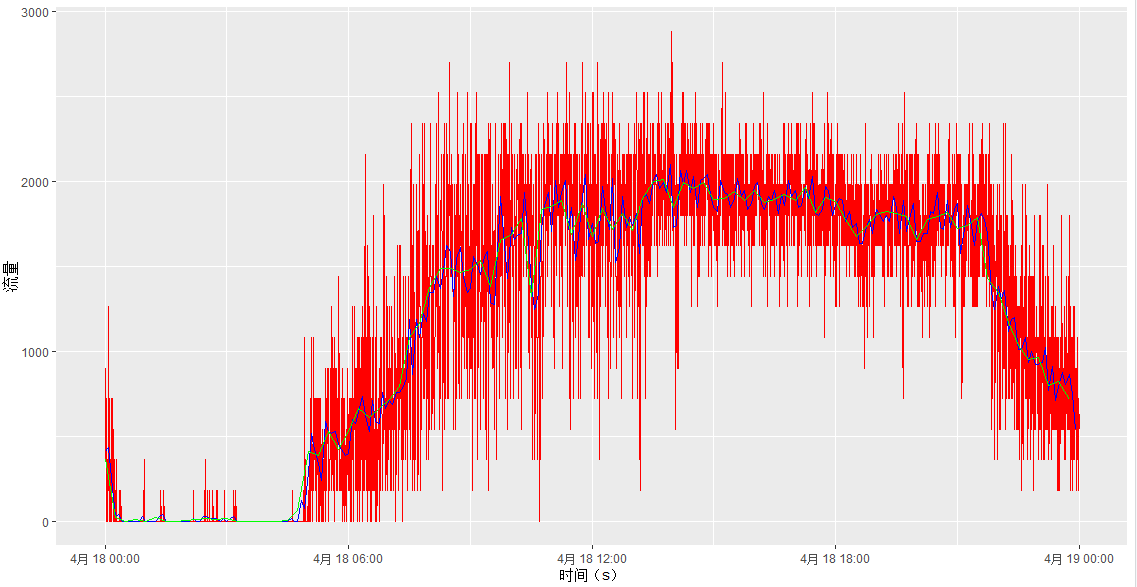
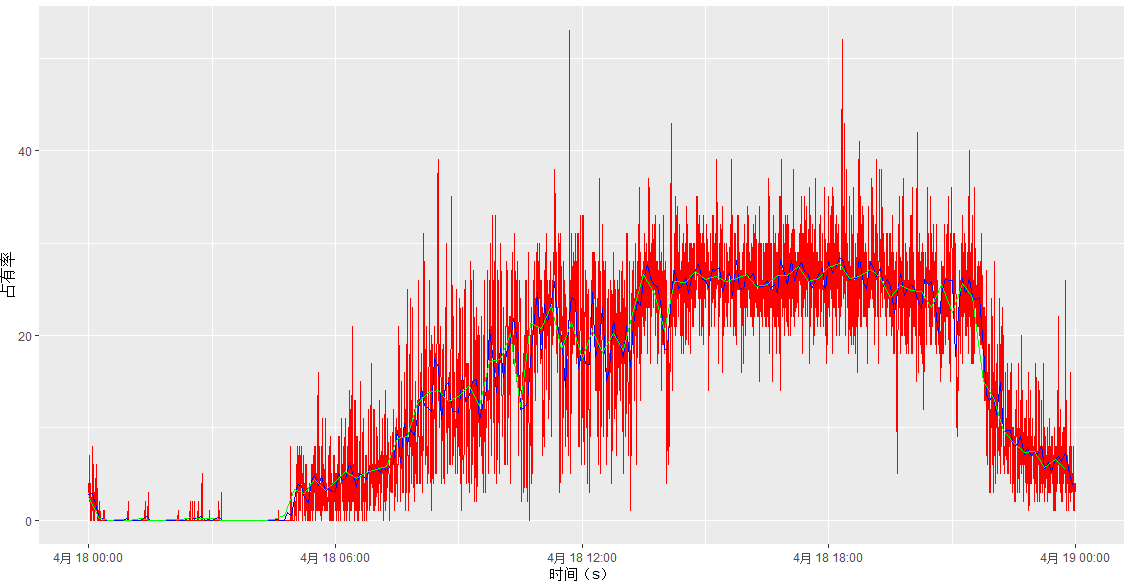



喜欢这篇文章的人也看了




评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果







